이번에는 GPT-1으로 더 잘 알려진 Improving Language Understanding by Generative Pre-training을
리뷰해보려고 한다.이 논문은 large unlabeled text는 방대하지만 태스크를 위한 라벨링 된 데이터는
적다는 사실에서 착안한 것으로, unlabeled text에 대해서는 generative pre-training을 수행하고
이후 실제 태스크에 대하여 discriminative fine-tuning을 수행하는 것을 키아이디어로 삼는다.
또한 이전 시도들과는 다르게 파인튜닝 과정에 있어서 task-aware input transformations을
수행함으로써 transfer의 효과를 극대화했다.
이러한 결과로 기존 모델의 구조에 최소한의 변화를 주고 최대한의 효과를 얻을 수 있었다고 한다.
1. Introduction
사실 unlabel된 텍스트를 통해서 supervised learning의 효과를 극대화하는 것은 예전부터 있어왔던
시도였다. 대표적으로 Word2Vec이 이에 해당한다. 하지만 단어 레벨의 정보 이상을 끌어내는 것은
어려운데, 그 이유로는 크게 두 가지가 있다.
1) transfer 과정에서 효과적인 learning objective는 무엇인지 모호하고.
2) 타겟 태스크에 learned representations를 어떻게 transfer할지 모호하다.
이 논문에서는 이 두 가지 문제점을 unsupervised pre-training and supervised fine-tuning으로
해결한다. 다양한 태스크에 최소한의 변화만 가지고 적용할 수 있는 universal representations를
얻기 위함이다. 훈련방법은 다음과 같다.
1. LM을 modeling objective로 사용한다. (unlabeled data)
2. 1에서 얻어진 parameter를 supervised objective에 대해서 사용한다.
모델링 구조로는 트랜스포머를 사용했다고 한다. 트랜스포머는 long-term dependencies에 대해서
recurrent한 모델과 다르게 구조화된 메모리를 훈련시킨다고 알려져 있다. 평가의 방법으로는
4개의 NLP task를 이용했다고 한다.(NLI, QA, semantic similarity, text classification)
2. Related Work
Semi-supervised learning for NLP
대표적으로 Word2Vec이 있다. labeling된 데이터와 그렇지 않은 데이터를 모두 훈련과정에 포함시키는 것을
일컫는다.
Unsupervised pre-training
사실 이는 전자의 특별한 케이스에 해당한다. 즉, semi-supervised learning이지만 supervised-learning의
good initial point를 찾는 것이라고 할 수 있다. 연구결과에 따르면 pre-training은 regularization처럼
작동한다고 알려져 있다.
또는 unsupervised pre-training에서 얻어진 hidden representations를 supervised learing의
auxiliary feature로 사용하는 방법이 있다.
Auxiliary training objectives
semi-supervised learning의 다른 형태로 target objective에 general한 objective를 사용하는 것
3. Framework
3.1 Unsupervised pre-training
$L_{1}(U) = \sum_{i}{logP(u_{i}|u_{i-k}, ..., u_{i-1};\Theta)}$
이 과정에서는 기본적인 language modeling objective를 사용했음을 알 수 있다.
그 다음으로 모델 구조는 multi-layer Transformer decoder를 사용했다.
$h_{0} = UW_{e}+W_{p}$
$h_{l} = transformerblock(h_{l-1}), i\in[1, n]$
$P(u) = softmax(h_{n}W_{e}^{T})$
3.2 Supervised fine-tuning
$P(y|x_{1}, ..., x_{m}) = softmax(h_{l}^{m}W_{y})$
$L_{2}(C) = \sum_{(x, y)}{logP(y|x^{1}, ..., x^{m})}$
$L_{3}(C) = L_{2}(C)+\lambda*L_{1}(C)$
pretraining에서 얻어진 hidden representation에 linear projection layer를 하나
추가한 후 타겟 태스크에 대한 비용함수가 $L_{2}(C)$에 해당한다.
여기서 주목해야 할 식은 마지막 식으로, pretraining에서 얻어진 파라미터를 그대로 사용하되
(즉, 새로 학습시키는 파라미터는 $W_{y}$와 delimiter tokens에 대한 임베딩 뿐이다.)
fine-tuning을 할 때 pretraining의 training objective도 learning objective에 사용한다.
이러한 과정을 도식화 한 그림은 다음과 같다.

3.3 Task-specific input transformations
위의 그림에서도 볼 수 있듯이 entailment, similarity 등에 대해서 delimiter 토큰이 들어간다.
이 섹션은 그래서 어떻게 input을 다르게 transformation 해서 transfer의 효과를 극대화했는지
설명해주는 섹션인데, 궁금하신분들은 원논문을 찾아보길 바란다.
4. Experiments
4.1 Setup
Unsupervised pre-training
BookCorpus dataset/1B Word BenchMark을 사용했다. 후자는 ELMo의 훈련에서도 쓰인
데이터셋이다.
Model specifications
masked self-attention을 사용한 12-layer decoder-only transformer를 사용했고
position-wise FFN에서 히든 차원을 3072로 늘렸다. 또한 기존 트랜스포머와 다르게
GELU를 사용했고 sinusoidal 포지션 임베딩말고 learned position embedding을
사용했다고 한다.
Fine-tuning details
Unsupervised training에서 얻어진 파라미터를 그대로 사용하고 마지막 linear layer
에서는 0.1 dropout을 사용햇다. $\lambda$는 0.5로 놓았다고 한다.
4.2 Supervised fine-tuning
evaluation에서 사용된 태스크를 수행할 때 쓰인 데이터셋을 설명한다.
5. Analysis
Impact of number of layers transferred, Zero-shot Behaviors

좌측 그림으로부터 layer 수가 늘어날 수록 train, dev 모두 정확도가 늘고 있고 이는 layer 수를 추가하는
inductive bias가 효과적임을 의미한다. 또한 우측 그림으로부터 pre-training update 수가 늘어날수록
성능이 좋아짐을 볼 수 있는데, 비교적 들쑥날쑥한 LSTM과 다르게 이 모델은 안정적으로 성능이 좋아진다.
이는 LSTM 모델 자체의 variance가 크고 트랜스포머는 그렇지 않다고 해석할 수 있다.
(안정적인 모델)
Ablation studies
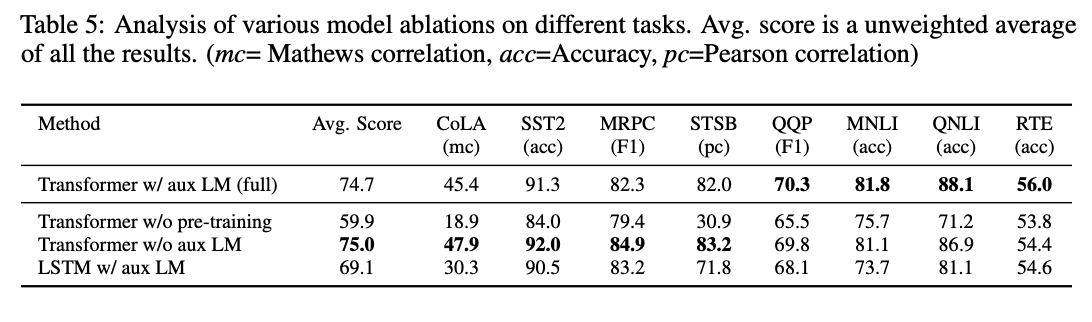
위의 표에서 볼 수 있는 것은 큰 데이터셋은 auxiliary objective가 도움이 되지만 작은 데이터셋은
그렇지 않다는 것이다.
6. Conclusion
이 모델의 의의는 generative-pretraining과 discriminative fine-tuning을 통해 task-agnostic한
single-model을 소개했다는 것이다.
사실 transfer 과정에서 linear layer하나만 들어가는 것과
learning objective를 혼합해서 사용한 것은 정말 훌륭한 아이디어라고 생각하지만 input transformation
과정이 조금 아쉽다는 생각이 들었다. 그것마저 neural network로 하기에는 무리가 있나..?
ELMo처럼 task-specific한 parameter를 추가해주면 어떨까하는 생각이 든다.
지적, 질문 모두 환영합니다! :)
이 글에서 쓰인 모든 이미지는 원본 논문에서 캡처한 것이며, 원본 논문의 링크는 우측에 있습니다. [링크]
'ML, DL > 논문 리뷰' 카테고리의 다른 글
| Generative Adversarial Nets 리뷰 (0) | 2020.11.20 |
|---|---|
| Auto-Encoding Variational Bayes 리뷰 (0) | 2020.11.09 |
| Why Should I Trust You? 리뷰 (0) | 2020.09.22 |
| Empricial Evaluation of Gated Recurrent Neural Networks On Sequence Modeling 리뷰 (0) | 2020.09.17 |
| Transformer-XL 리뷰 (0) | 2020.09.14 |