논문 링크: https://arxiv.org/abs/1703.04247
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
Learning sophisticated feature interactions behind user behaviors is critical in maximizing CTR for recommender systems. Despite great progress, existing methods seem to have a strong bias towards low- or high-order interactions, or require expertise featu
arxiv.org
본 논문은 Wide & Deep Learning for Recommender Systems (https://arxiv.org/abs/1606.07792)를 발전시킨 논문으로, CTR prediction에 대한 논문이다.
1. Wide & Deep 리뷰
먼저, Wide & Deep에 대한 소개를 간단히 하고 넘어가겠다. 아래는 Wide & Deep architecture를 그림으로 표현한 것이다.

Wide 파트는 피쳐간의 low-order interaction을 잡아내기 위한 네트워크로, cross transformation을 사용한 glm(generalized linear model)에 해당한다. Cross transformation이란 binary feature간 상호 작용을 위한 피쳐 변환에 해당하는데, 식은 다음과 같다.

k는 k번째 변환, i는 i번째 피쳐를 뜻한다. AND(gender="female", english="english")와 같이 이미 도메인 지식으로부터 밀접하다고 알려진 피쳐들의 co-occurence이다.
따라서 manual feature engineering이 필요하고, 데이터가 크고 피쳐가 매우 많은 상황에서는 적합하지 않다.
Deep 파트는 categorical 피쳐를 dense real-valued 벡터로 임베딩해서 사용하는데, 원-핫 인코딩을 사용했을때보다 차원이 축소되는 효과가 존재한다. (또는 하나의 피쳐 카테고리를 실수 벡터로 사용함으로써 표현력이 증가하는 효과도 있을 수 있다.)
그 외에는 일반적인 feed-forward neural network 구조를 가진다.

최종 예측은 위 처럼 Wide 파트의 아웃풋과 Deep 파트의 아웃풋, bias를 합한 결과를 sigmoid 레이어에 넣어서 구한다.
2. DeepFM 설명
2-1. Introduction
CTR 예측에서의 key challenge는 피쳐간의 interaction을 효과적으로 모델링하는 것으로, 크게 두 가지 방법이 있음을 주장한다.
- 도메인 지식에 따라 디자인하는 방법: 효과적이지만 위와 같은 상황에서는 현실적으로 힘들다.
- 머신러닝 학습과정으로부터 automatically capture
- 기저귀 & 맥주처럼 보기에는 관계가 없어보이지만, 상관계수가 0.9를 넘는 피쳐들이 존재한다.
- Generalized Linear Models: 현업에서 비교적 안정적이고 우수한 성능을 보여주지만, 피쳐간 상호작용을 잡아내기엔 표현력이 부족하다.
- Factorization Machines: 피쳐의 latent vector를 내적함으로써 pairwise feature interaction을 모델링한다.
일반적으로는 complexity 문제로 인해 2nd order 까지만 사용하며 latent vector를 효과적으로 학습하기 위한 방법으로는 DNN을 이용한 임베딩 학습이 있다.
다만 서술한 위의 두 가지 방법으로는 low-order feature interaction만을 학습할 수 있기 때문에,
high-order feature interaction을 학습해야하는 니즈가 존재하며 일반적으로 DNN을 이용하여 이를 해결한다.
이 논문에서는 현존하는 방법들의 문제점으로 두 가지를 제시한다.
- Biased to low or high feature interaction: Wide & Deep을 예시로 들자면, 학습이 고루되지 않고 wide / deep 파트 중 하나에 편중되어 학습된다는 것이다.
- Rely on feature engineering: Cross transformation 같은 manual feature engineering을 필요로 한다는 문제점이 있다.
2-2. Factorization Machines
DeepFM 구조를 설명하기 전에 Factorization Machines(이하 FM)에 대해 짚고 넘어가려고 한다. (https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf)
FM은 SVM과 factorization model의 장점을 결합한 모델이다.
- SVM: 어떤 인풋에도 작동하는 general predictor지만, 데이터가 매우 sparse할 때 complex kernel space에서 안정적인 파라미터 학습이 어렵다는 문제점이 존재한다.
- Factorization model: 피쳐간 interaction을 잡아내는데 적합하지만 일반적인 예측 데이터에 사용하기 위해서는 별도의 고안된 알고리즘이 필요하다.
즉, high-sparsity 상황에서도 피쳐간 interaction을 모델링하는 general predictor에 해당한다.
그렇다면 SVM 모델이 왜 high-sparsity 상황에서 학습이 제대로 되지 않는지 살펴보자.

SVM은 input $\mathbf{x}$를 kernel space로 transform한 다음 파라미터 벡터 $\mathbf{w}$와 내적하여 $y$를 예측한다. Kernel space에는 여러가지가 존재하지만, 예시로 polynomial kernel 하나만을 들겠다.

degree가 2일때 polynomial kernel은 위와 같다. 따라서 degree=2인 polynomial kernel에서 SVM의 구조는 아래 식과 같아진다.

전체 학습해야할 파라미터의 시간복잡도는 $\mathcal{O}(n^2)$이 된다.
이제 위 식을 염두에 두고, FM의 prediction equation을 보자.

$w_{0}$는 global bias, $w_{i}$는 i번째 변수의 강도, $\hat{w}_{i, j} = <\mathbf{v}_{i}, \mathbf{v}_{j}>$는 i번째 변수와 j번째 변수의 상호작용을 의미한다.
이때 $<\mathbf{v}_{i}, \mathbf{v}_{j}>$는 i번째 변수의 latent vector와 j번째 변수의 latent vector의 내적을 뜻한다.
전체 학습해야할 파라미터의 시간복잡도는 $\mathcal{O}(nk)$가 된다.
$k$가 충분히 클 때, 다시 말해 latent vector의 차원이 충분히 클 때 high-sparsity 상황에서는 행렬의 rank가 낮아지므로 충분히 데이터를 잘 표현할 수 있으며 better generalization이 가능하다. (학습할 파라미터 수 감소)
그렇다면 이제, high-sparsity 상황에서 왜 FM이 SVM 보다 우위에 있는지 알아보도록 하겠다.
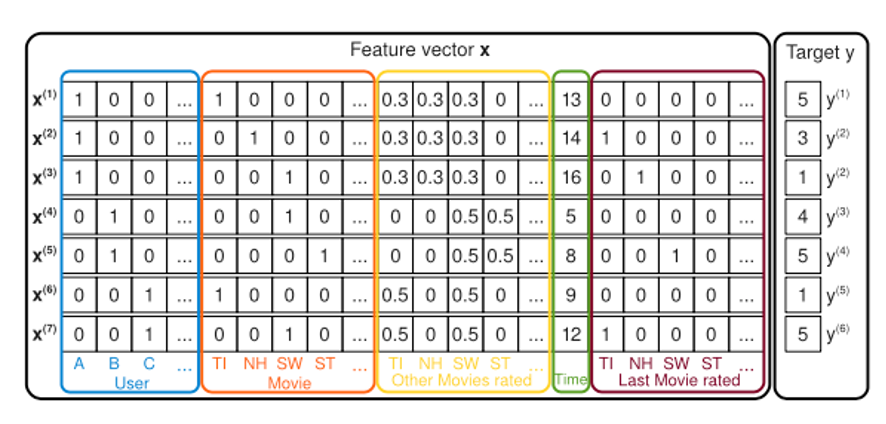
위 그림은 Recommendation System에 사용되는 일반적인 데이터를 예시로 든 것이다. (CTR prediction도 추천의 범위에 속한다.)
A 사용자가 Star Trek(ST) 영화를 본 케이스가 없으므로 SVM의 direct estimate는 no interaction이 될 것이다.
그러나 FM에서는 이와 같은 경우도 피쳐간의 interaction을 학습할 수 있다. 사용자 B가 Star Wars(SW), Star Trek(ST)를 봤을 때 비슷한 interaction을 했으므로 Star Wars의 latent vector와 Star Trek의 latent vector는 유사할 것이다.
따라서 <User A, Movie ST> ~= <User A, Movie SW>가 된다.
마지막으로, FM의 시간복잡도를 $\mathcal{O}(kn^2)$에서 $\mathcal{O}(kn)$으로 줄일 수 있는데 증명은 아래에 첨부해놓았다.
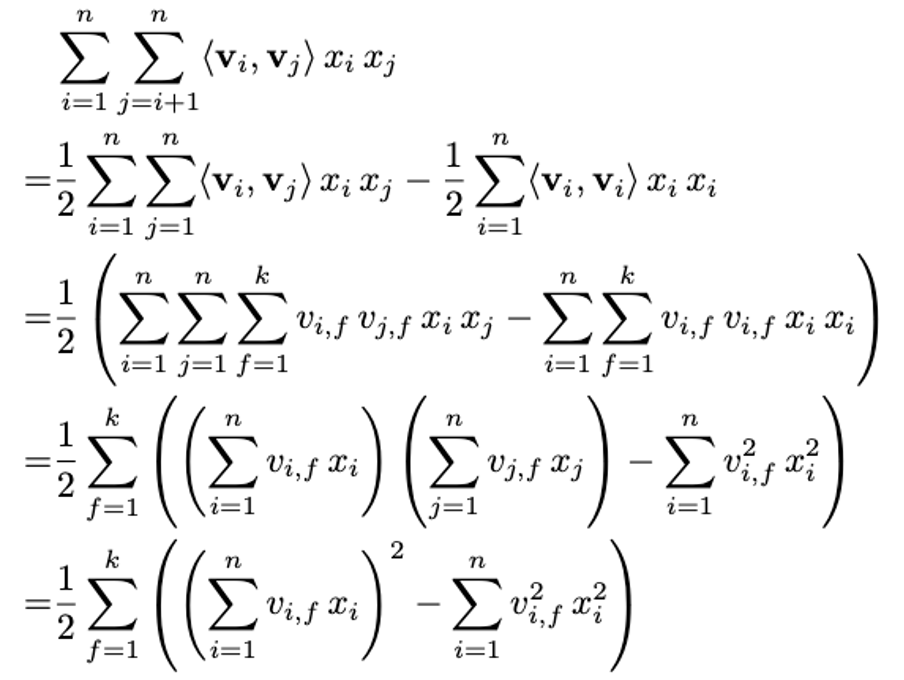
2-3. DeepFM 구조

DeepFM도 Wide & Deep과 비슷하게 FM 파트와 DNN 파트를 합해서 결과를 구한다.
최종 아키텍쳐는 아래와 같다.
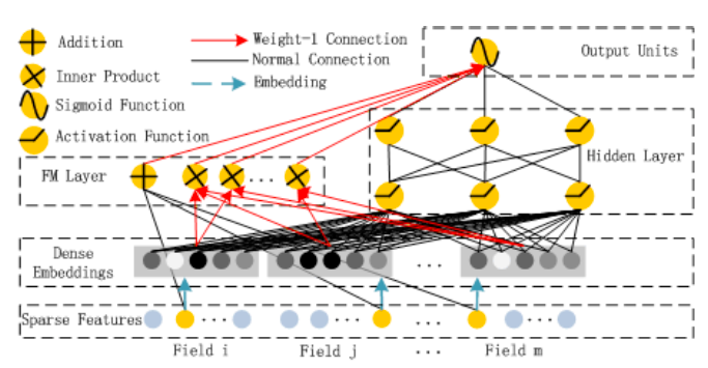

$<w, x>$부분은 linear (order-1) interaction에 해당하고, 뒷부분은 latent vector간의 내적으로 모델링한 pairwise interactions 부분이다. 주목할 점은 FM layer와 DNN layer의 임베딩을 같이 사용함으로써 임베딩 벡터가 low, high interaction에 모두 적합하도록 학습된다는 것이다.
3. 결론 및 시사점
마지막으로 결론 및 시사점에 대해 내가 느낀 바를 정리하고 글을 마무리 지으려고 한다.
- 피쳐간의 low-order & high-order interaction을 모두 고려한 아이디어로, 별도의 피쳐 엔지니어링이 필요없이 low-order interaction을 모델링할 수 있다.
- Low-order & high-order에 동일한 피쳐 임베딩을 사용함으로써 한 쪽에 편향된 학습이 이루어지지 않도록 한다.
'ML, DL > 논문 리뷰' 카테고리의 다른 글
| Generative Adversarial Nets 리뷰 (0) | 2020.11.20 |
|---|---|
| Auto-Encoding Variational Bayes 리뷰 (0) | 2020.11.09 |
| GPT-1 리뷰: Improving Language Understanding by Generative Pre-training (0) | 2020.09.30 |
| Why Should I Trust You? 리뷰 (0) | 2020.09.22 |
| Empricial Evaluation of Gated Recurrent Neural Networks On Sequence Modeling 리뷰 (0) | 2020.09.17 |