
이 글은 하이브 완벽 가이드 책을 읽고 그 중 일부 내용을 정리한 글입니다.
하둡의 런타임 모드 - 로컬 모드, 의사 분산 모드, 분산 모드
하둡의 기본 런타임 모드는 로컬 파일시스템을 사용하는 로컬 모드입니다. 이 모드에서는 하이브 쿼리를 포함하는 하둡 잡이 실행될 때 맵 태스크와 리듀스 태스크가 동일한 프로세스에서 동작합니다.
실제 클러스터는 분산 모드로 설정합니다. 파일시스템에 대한 URI 정보가 없을 때는 이 클러스터의 분산 파일시스템(보통 HDFS)을 기본값으로 사용합니다. 잡은 이 클러스터 상의 잡 트래커에 의해 리되고 각각의 태스크는 각기 다른 프로세스에서 동작합니다.
개인용 컴퓨터를 사용해서 작업할 경우에는 의사 분산 모드로 동작하도록 설정합니다. 의사 분산 모드는 분산 모드와 같게 동작하는데, 즉 파일시스템은 분산 파일 시스템을 기본으로 참조하고 잡은 잡 트래커 서비스로 관리합니다. 다른 점은 하나의 컴퓨터라는 점입니다. 따라서 HDFS 블록의 복사 개수를 하나로 제한하며, 이는 노드가 하나인 클러스터와 동일하게 동작합니다.
팁) 작은 크기의 데이터에 대해서 로컬 모드로 하이브 쿼리를 수행하면 훨씬 빠른 결과를 얻을 수 있습니다.
-- 하이브 테이블에 저장될 실제 데이터를 로컬 파일시스템 상의 어느 위치에 보관할지 결정
SET hive.metastore.warehouse.dir=/home/me/hive/warehouse;
SET hive.exec.mode.local.auto=true;
하이브의 구성
하이브 바이너리 배포판의 코어는 자바 코드로 된 세 부분으로 구성되어 있습니다. hive-exec.jar, hive-metastore.jar과 같은 JAR(자바 아카이브) 파일들이 이에 해당되며 $HIVE_HOME/lib 디렉터리 아래에 있습니다.
$HIVE_HOME/bin 디렉토리에는 CLI와 같이 하이브의 여러 서비스를 실행시킬 수 있는 실행 스크립트가 있습니다.
또한 하이브는 다른 프로세스에서 원격으로 접근할 수 있도록 해주는 쓰리프트 서비스를 가집니다. 하이브가 제공하는 JDBC와 ODBC로 접근할 수 있는 방법은 이 쓰리프트 서비스 위에서 동작합니다.
메타 스토어 서비스는 테이블 스키마와 같은 메타데이터를 저장하기 위해 존재합니다. 보통 메타스토어는 MySQL과 같은 관계형 데이터베이스의 테이블로 구현됩니다. 메타 스토어는 CREATE TABLE, ALTER TABLE 등과 같은 명령을 수행할 때 명시되는 테이블 스키마와 파티션 정보와 같은 메타 데이터를 저장하고 있습니다. MySQL을 주로 사용합니다.
-- 메타 스토어 데이터베이스 확인
SET javax.jdo.option.ConnectionURL;
마지막으로 원격으로 하이브에 접근할 수 있는 웹 인터페이스인 HWI를 제공합니다.
conf 디렉터리에는 하이브를 설정하기 위해 필요한 파일들이 있습니다. 메타스토어, 최적화 방법, 제어 방법 등을 설정할 수 있습니다.
명령행 인터페이스(CLI) 사용하기
hive --service cli --help 명령을 사용하면 CLI에 대한 간단한 도움말을 출력해줍니다.
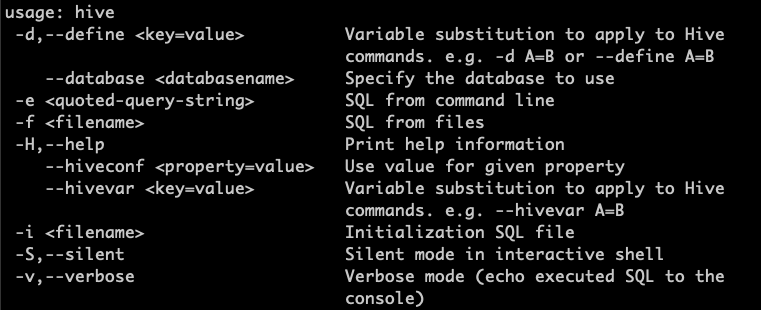
--define key=value 옵션은 --hivevar key=value 옵션과 동일하게 동작합니다. 이 두 옵션은 하이브 스크립트에서 사용자 정의 작업을 수행하기 위해 참조할 사용자 정의 변수를 정의합니다. 쿼리가 처리기로 보내기 전에 쿼리에 있는 변수는 CLI 내에서 바뀌게 됩니다.
네임스페이스 옵션은 아래와 같습니다.
| 네임스페이스 | 접근 | 설명 |
| hivevar | 읽기/쓰기 | 사용자 정의 변수(0.8.0 이후) |
| hiveconf | 읽기/쓰기 | 하이브만의 설정 속성 |
| system | 읽기/쓰기 | 자바가 정의한 설정 속성 |
| env | 읽기 | 쉘 환경에서 정의한 환경 변수 |
CLI 내부에서는 SET 명령을 사용해서 변수를 나타내고 변경합니다. hivevar 옵션 외에 hiveconf, system, env 네임스페이스에 있는 속성을 사용할 때에는 접두사를 반드시 사용해야 합니다. 아래는 예시입니다.
-- env 네임스페이스의 HOME 변수 확인
SET env:HOME;
--- hivevar, hiveconf, system, env 네임스페이스 모든 변수 출력
SET ;
-- HDFS, 맵리듀스를 제어하기 위해 설정한 모든 하둡 속성 출력
SET -v;
-- 쿼리 컬럼 헤더 출력
SET hive.cli.print.header=true;
-e 옵션은 하나 또는 세미 콜론으로 구분된 여러 쿼리를 수행한 후에 하이브 CLI를 곧바로 빠져나올 수 있게 해줍니다. 쿼리 결과를 바로 파일에 담기 위해 이 기능을 사용하는데, -S 옵션을 추가하면 불필요한 출력이 출력되지 않습니다.
다음 예제는 warehouse의 속성명이 기억나지 않을 때 사용할 수 있는 트릭입니다.
hive -S -e "set" | grep warehouse
-f 옵션은 파일에 저장된 하나 이상의 쿼리를 실행하기 위해 사용됩니다. 일반적으로 하이브 쿼리가 저장된 파일은 .q 또는 .hql 확장자를 이용합니다.
하이브는 $HIVE_HOME 디렉토리에서 .hiverc 파일을 자동으로 찾는데, 만약 파일이 존재한다면 파일 안에 있는 명령을 수행합니다. 따라서 자주 사용되는 명령을 .hiverc 파일에 등록할 수 있습니다.
하이브 CLI 내에서 hadoop dfs ~ 명령을 수행할 수 있는데 dfs -ls; 처럼 hadoop을 빼주면 됩니다. dfs -help; 명령을 수행하면 dfs에서 지원하는 모든 옵션의 도움말을 볼 수 있습니다.
'Hadoop Ecosystem > Hive' 카테고리의 다른 글
| [하이브 완벽 가이드] Ch8. HiveQL : 색인(Index) (0) | 2022.10.04 |
|---|---|
| [하이브 완벽 가이드] Ch6. HiveQL : 쿼리 (0) | 2022.09.19 |
| [하이브 완벽 가이드] Ch5. HiveQL : 데이터 조작(DML) (0) | 2022.09.16 |
| [하이브 완벽 가이드] Ch4. HiveQL : 데이터 정의(DDL) (0) | 2022.09.12 |
| [하이브 완벽 가이드] Ch3. 데이터형과 파일 포맷 (2) | 2022.09.11 |